
Computer Vision · Multi-Modal Generative AI · Reinforcement Learning
Jianxiong Shen
I am currently a Research Scientist at Tencent in Shenzhen. My work spans Game Agents, Multi-Modal Generative AI and Reinforcement Learning.
I received my Ph.D. from the Polytechnic University of Catalonia (UPC) in 2024, advised by Francesc Moreno-Noguer and Adria Ruiz. Before that, I received my B.Eng. and M.Eng. degrees from Harbin Institute of Technology.
Recent research
Experiment-driven studies of RL post-training across LLMs, VLMs and Diffusion Models.
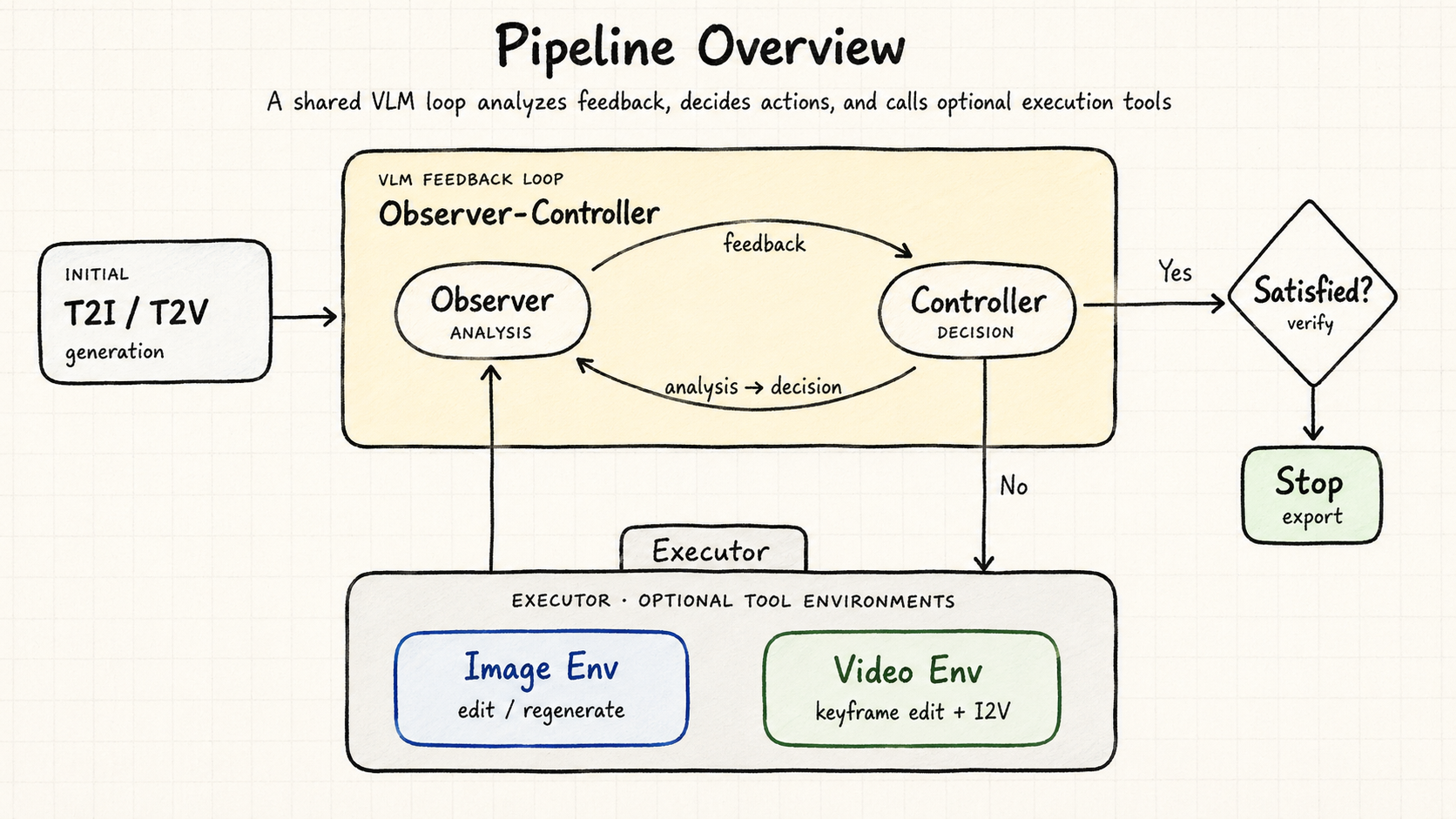

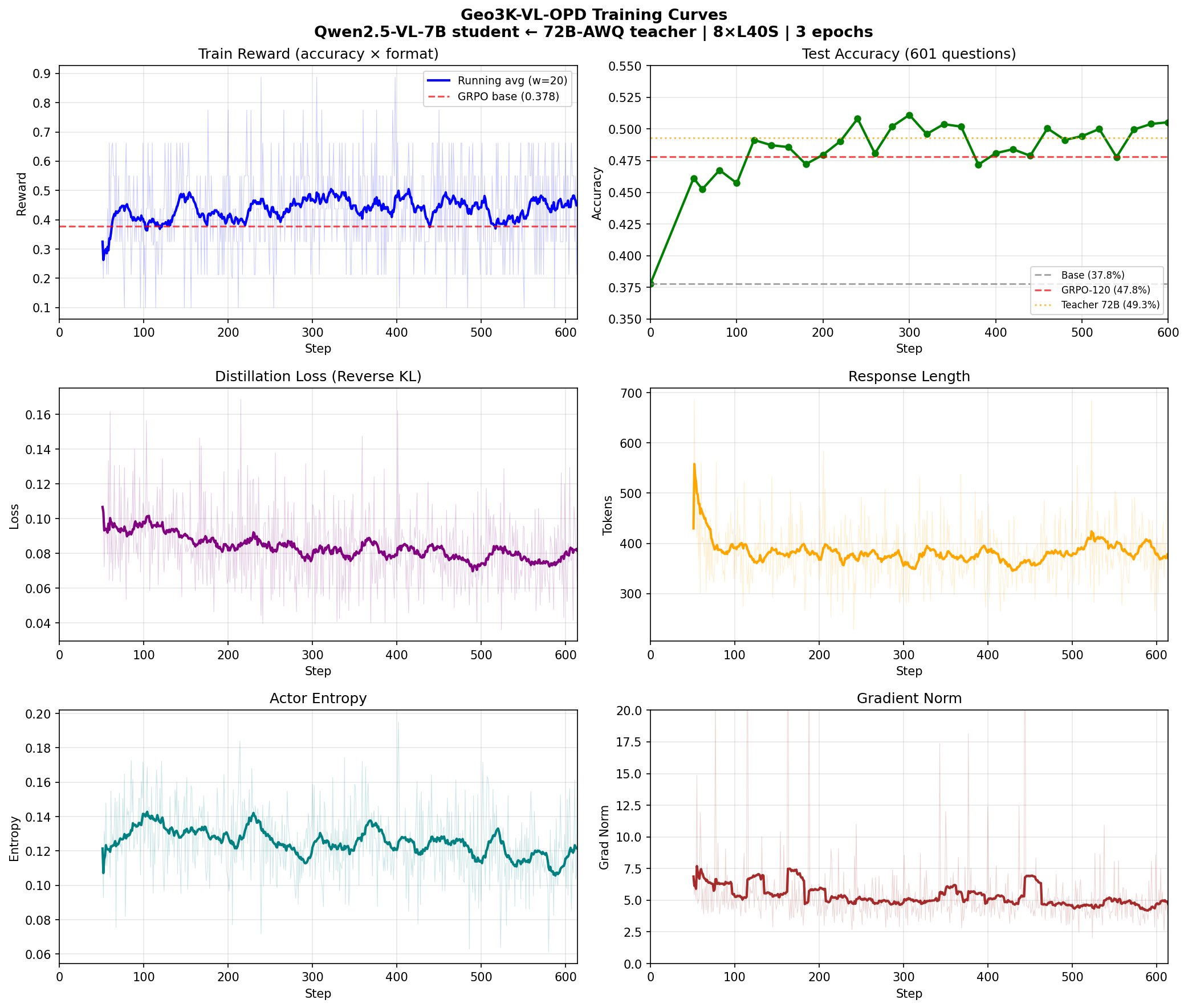
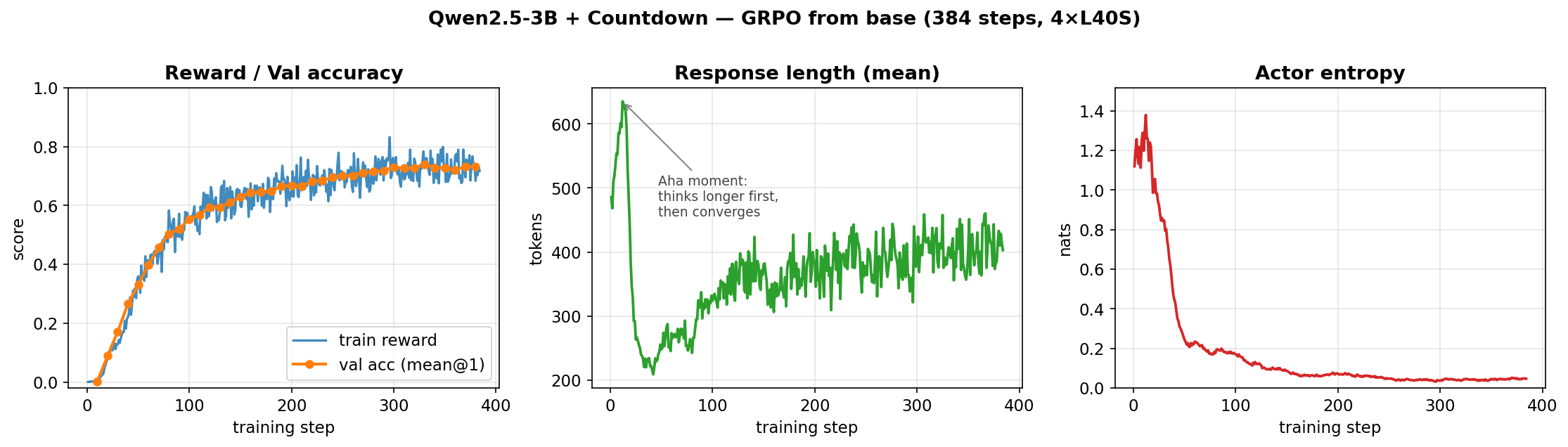
R1-Zero Style Reasoning and Transfer
Reproduced emergent GRPO reasoning at 3B scale and measured where the learned search behavior transfers, including both positive and negative results.
Selected first-author work
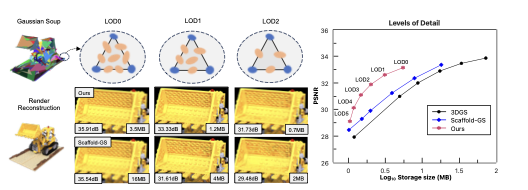
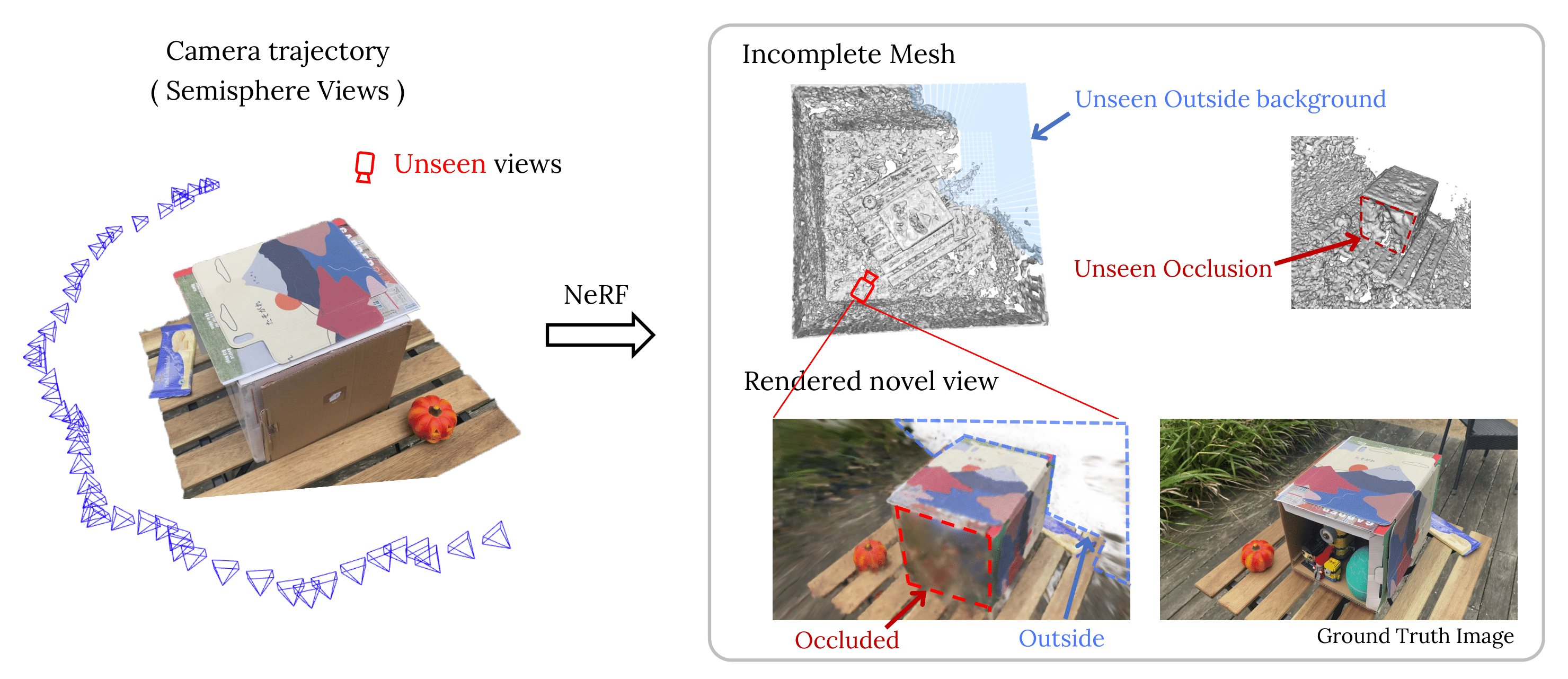
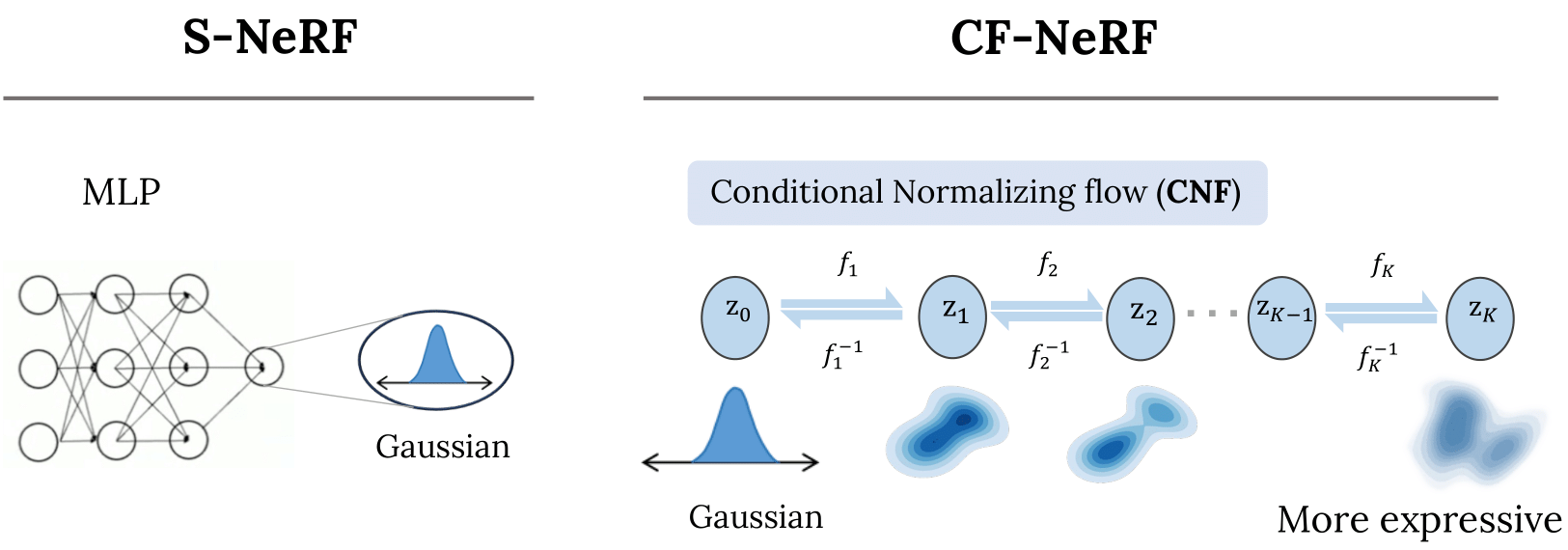
Four projects tracing a path from reliable 3D reconstruction to efficient neural rendering.

Experience & education
Research Scientist · Tencent
Game reinforcement learning, multimodal agents, and post-training research.
Ph.D. · Polytechnic University of Catalonia
Computer vision and 3D scene modelling at the Institut de Robòtica i Informàtica Industrial. Thesis awarded Excellent Cum Laude.
B.Eng. & M.Eng. · Harbin Institute of Technology
Engineering education and early research in computer vision.
Recent news
Published a technical blog connecting Flow-GRPO, DiffusionNFT, and interactive generative agents.
Released a short empirical note on scene collapse under OCR-reward diffusion RL.
LOD-GS was published at CVPR 2025.
Joined Tencent as a Research Scientist.
Completed my Ph.D. with Excellent Cum Laude.
Presented our work on 3D uncertainty fields at ICRA 2024.